What is Data Labeling?
What is Data Labeling?
Let us understand a small portion of the world of Artificial Intelligence and Machine Learning. We will learn about Data Labeling which is the most vital and time-consuming process in your Machine Learning Project. We will also get a brief understanding of data labeling tools and services and their applications and importance in Machine Learning.
What is Data?
Anything that helps us add an attribute to an object, sound, text, etc. i.e. Any information we comprehend through our five senses and processes in our brain can, in some form, be considered as data. This data plays a vital role in the decisions we take daily.
For example, if you notice that it’s raining outside and you have some work, you tend to observe and note the intensity of the rain and with your eyes and ears and your brain processes this information, deciding whether you should carry an umbrella or postpone the appointment.
Data is one of the highest value assets in today’s world of Artificial Intelligence (AI) and Machine Learning (ML) as it can be similarly implemented to make a digital program understand the process, learn it and execute the task which it is designed for.
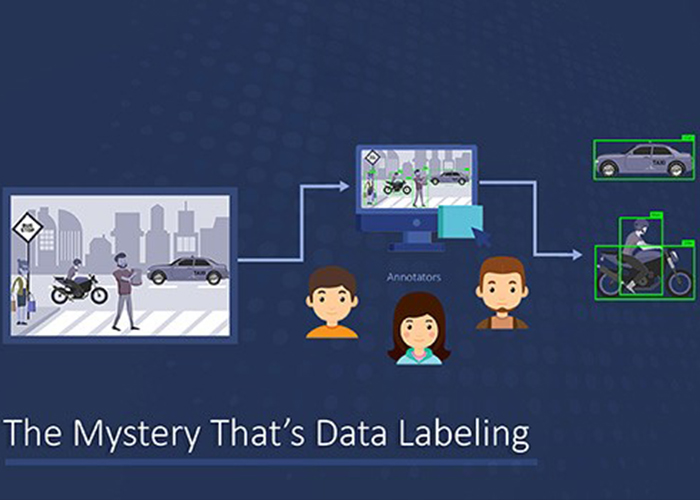
What is Data Labeling?
Data labeling is the process of generating labeled data sets. These data sets are used as training data sets in Machine Learning. ML Models assess the labeled data and recognize repetitive patterns. After processing a certain number of repetitive data sets, the ML Model learns to detect and tag unlabeled data. Data labeling is also commonly known as Data Annotation, Data Tagging, Data Classification, etc.
Data labeling plays a role in identifying unlabeled raw data such as images, text, speech, video, etc., and adding possibly multiple labels to the data which help the ML Model to learn. For example, data labels help the ML Model decide the contents of an image, tone, or sentiment of texts and audio, object identification in videos, and so on.
The process of Data Labeling
Train, Test, HITL, QA, Scale
Train – Labelers work on creating the apt data sets for your project and feed them to your ML Model. This trains the AI and helps it discriminate between input data, based on the data sets fed to the system. For example, A data set with details of all fruits will help the AI determine if there are any fruits in the input data and if there are, which fruits are they?
Test – Once a labeled data set (Ground Truth) is uploaded to the ML Model, it is tested in real-world situations to note the percentage of accuracy of the tasks executed by the ML Model (During initial tests, it is rare to get an extremely high accuracy percentage).
Human in the Loop (HITL) – As the name suggests, ‘HITL’ or ‘Human in the Loop’ means an actual trained human being acts as an integral part of the training and testing process where any output by the ML model is thoroughly assessed by the human and accordingly changes are made to the model. HITL is a very vital element of Data Labeling as it helps the process learn more about things that are more comprehensible to humans, such as, the emotion of a person, the tone of voice input, etc. If certain data is too complicated for the ML model, it redirects the data as ambiguous data to the human, who labels it manually and feeds it back to the machine to learn it and evolve.
Quality Assurance (QA) – QA is one of the most important tasks in Data Labeling. Once the ML Model starts detecting and labeling data based on the ground truth, a simultaneously run QA process detects any errors in the ML model’s functioning and this feedback helps the labeler to calibrate the training data-set to ensure that the algorithm of the ML model works perfectly and detects and labels objects in the real world. When the entire process is divided into multiple atomic tasks and a QA is set to all atomic tasks, the accuracy of the ML Model increases drastically.
Operationalization – Here, we place the ML Model in the real world, and it will process data that it encounters and initiate steps accordingly. It absorbs new data and learns, based on the data labels detected by it. The AI should be functioning well, meeting its required target efficiently. At this point, comes your next decision. Does the current flow of work suffice your requirements, or do you need to scale your ML Model to meet the size of your tasks?
Scale – Scaling your operations results in the need to scale your ML Model. This could be tricky as the algorithm should be designed in such a way that there is room for flexibility. So, when the processes scale up, the ML Model can run the increased volume of data labeling tasks. Here, your data labeling team plays an important role. They need to be agile so they can quickly make the required changes for the scaling of the data labeling process. This flexibility also helps when there are iterations that need to be done to the program according to your changing requirements.
TYPES OF LABELING -
Data labeling is divided into different types based on the flow of the process. Some examples are Semantic Segmentation, Bounding Box, Key-Point Annotation, Polygon, Cuboid, 3D Point Cloud, Text Annotation, etc. Let us understand them in brief –
Semantic Segmentation – It is a labeling type where your ML Model separates different elements in the image by highlighting each pixel of the element making every element distinguished from the other. Pixel-wise labeling gives a highly accurate representation of different elements. This kind of dense prediction technique helps the ML Model distribute a digital image into different segments and label each segment.
Bounding box – This is a widely known type of annotation. The object in an image is outlined by a rectangular box. The deep learning model uses these inputs for comparison with the training data set and accordingly labels the new data.
Cuboid – This is exactly like a bound box but in 3D. The object in an image is outlined on 3 axes, giving an idea of the length, breadth, and depth of the object.
Key point annotation – As the name suggests, this type of data labeling marks the key-points of the object in a digital image which helps the ML Model determine the posture of the object. For example, key points such as eyes, nose, neck, abdomen, elbows, wrists, knees, ankles, etc. help determine if a human is standing, walking, or running.
Polygon – This type of data labeling is used to understand the structure of an object. To do this, the labeling tool outlines the object in pixel-perfect polygons.
3D Point Cloud – Here, the Labeling tool marks multiple points in the 3D space in which the object is present. More number of 3D points gives higher accuracy.
Text Annotation – It is used for detecting and labeling text in an image. The labels are according to the text detected in the image.
Data labeling approaches -
Data labeling is one of the most tedious and time-consuming tasks in the process of setting up your Machine Learning or Deep Learning Projects. About 83% of your AI project time is spent in gathering, cleansing, and labeling data. This wrangle of data uses the crucial time of your data scientists, researchers, and data labelers which is expensive. If you decide to outsource your data labeling requirements, your in-house team can be utilized for more critical activities such as testing and tuning the AI in real-time situations.
Now, even though it’s a cost-effective option, outsourcing your data labeling requirements by freelancers might backfire and prove inefficient for the project, if the labeling team is not managed well.
Keeping this in mind, let us have a look at the different data labeling approaches you may take –
In-House Team– Your In-House team of data scientists themselves does the data labeling (which is extremely time-consuming and non-cost-effective).
Outsourcing- You outsource your requirements to a freelancer or crowdsource when you have requirements on a larger scale (which holds your data security at risk).
However, these approaches have their set of problems as stated above. Here’s another option-
Crowdsourcing- You work in collaboration with managed teams who specialize in Data Labeling and are well trained in data management and data security which is essential.
In this case, you hire a Data Labeling team that will comply with your set of terms and provide excellent support in your labeling needs.
This team covers a lot of aspects that come under data labeling –
1) Proficient use of a Data Labeling tool.
2) Quality Assurance (QA) and High Accuracy in functioning.
3) Iterations and changes in labeling which you may require for your ML Model, based on tests and trials.
4) Flexibility in work and a solid communication loop.
Automaton AI’s Data labeling team provides end-to-end Data Labeling services.
Labeling tool- You resort to a fully automated data labeling tool which drastically increases the pace of your data labeling tasks by taking care of the Labeling cycle from Data Preparation to QA.
ADVIT by Automaton AI provides a full stack Data Labeling tool.
ADVIT is a complete solution to all your data labeling needs. It is an Automated labeling tool which can be customized according to your use cases to detect and label the data.
A Hierarchical Attribute Tagging
ADVIT features a hierarchical attribute tagging letting you label products according to their category and subcategory and so on.
Multi-Camera Synchronization
ADVIT also features real-time multi-camera synchronization which keeps a track of the timestamps of every frame to detect and synchronize the same object from different cameras.
Data Security
Data Security is of utmost priority and ADVIT ensures that by canceling out the necessity to share any data on the cloud and by preventing any unauthorized access to users.
Seamless Integration
It features the most efficient integration with your software stack.
Customizable Format Outputs
ADVIT can output the data in various formats depending on your requirement, like .txt, .json, .csv, etc.
Cost-effective
ADVIT saves a lot of your operational costs and boasts a zero start-up cost.
So, we have understood what data labeling is, and how important it is to choose the right tools and the right data labeling team for your ML Project.